Hello,
let’s take the following description inside a logical component of our system.
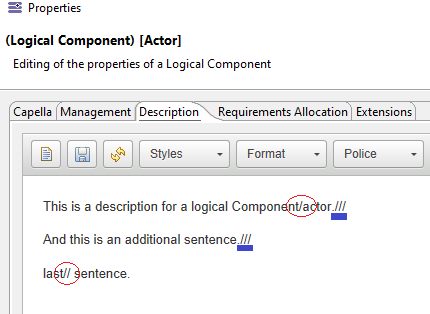
Using the Tokenize function :
selection.eAllContents(la::LogicalComponent)->at(14).description.tokenize(‘///’)
to obtain 3 sentences would not work well.
For the simple reason, there is a “/” inside the first sentence. And a “//” in the third sentence. Thus, obtaining 5 sentences.
My question:
How comes .tokenize(‘///’) does include .tokenize(‘//’) and .tokenize(‘/’) ?
Isn’t it possible to have a tokenize function that separates text only if it has seen “///”? (Meaning it should be doing nothing if it sees “/” or “//”)
Thanks again.
Edit: It’s especially bothersom because the HTML codes contain “/” such as ('<'b/> etc), and the tokenize function would not work on a type returned by fromHTMLBodyString() , but that’s not the only problem expressed here.