To solve this paradox I’ve introduced FncBlock notation to be used to decompose atomic functions to smaller blocks without decomposing them into sub functions.
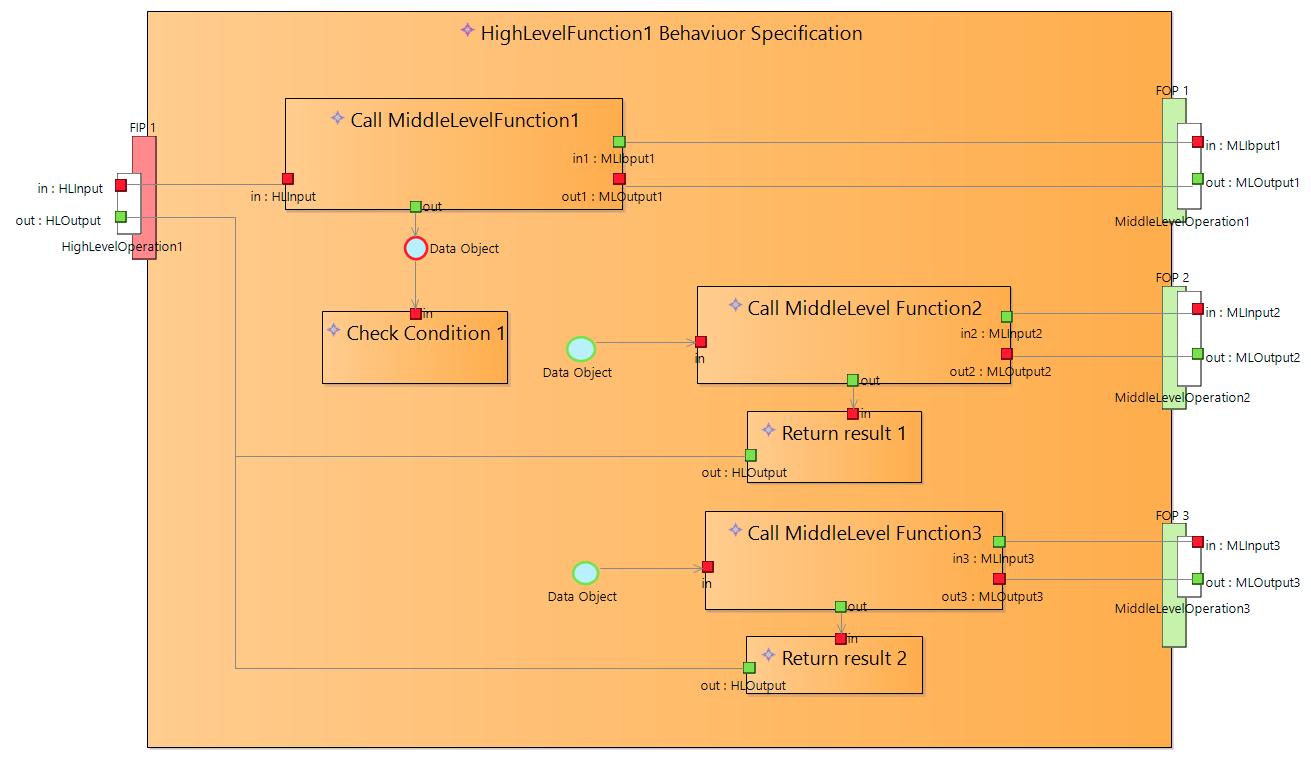
FncBlocks are similare to Capella functions. The main difference that data transfer are modeled in more detail. FncBlocks are connected via data exchanges and data ports that can be typed by any DataType.
External data ports are mapped to ExchangeItemElements of atomic function ports.
Diagram above defines data flow between FncBlocks.
Using FncBlocks we can decompose any atomic functions into smaller blocks and define behaviour based on these smaller blocks. To define behaviour (control flow) we can “use” FncBlocks from statecharts, BehaviourTrees and activities. What way we use to define behaviour depends on the behaviour type. In all cases we define behaviour in terms of defining control flows of FncBlocks.
FncBlocks was introduced during my reasearch of applicability of BehaviourTree notation for defining behaviour in Capella. But they can be used not only with BTrees but with statecharts also.
More information about using FncBlocks with BehaviourTrees can be found staring from this post in the BTree topic