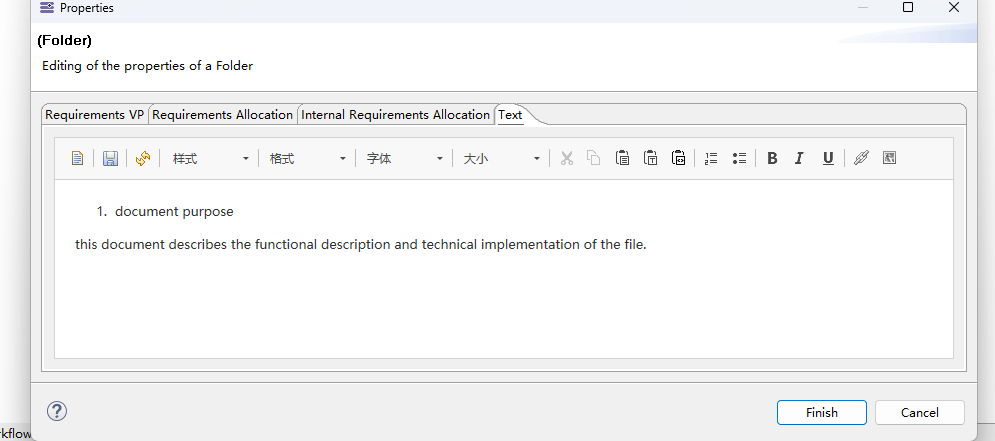
how to only acquire the first line of this paragraph? split() function and substring function doesn’t seem to work.
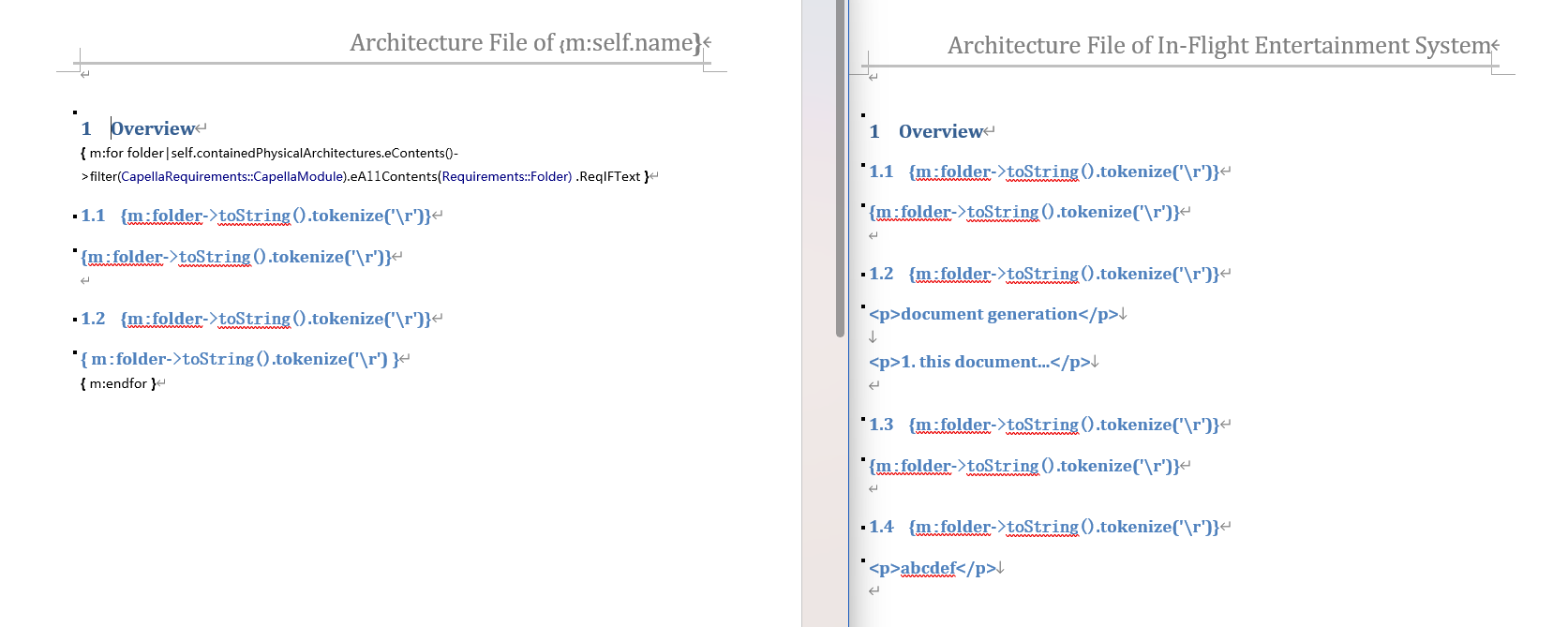
here is my template and the generated file.
it seems some titles can’t acquire aql expressions.
and how to acquire the rest of the lines? substring doesn’t seem to work
You can use the following expression to replace all end lines to let say ‘\n’ and then split on ‘\n’.
folder.toString().replaceAll('(\r\n)|\n','\n').tokenize('\n')->at(1)
You can also loop on each line:
{m:for line | folder.toString().replaceAll('(\r\n)|\n','\n').tokenize('\n')}
{m:line}
{m:endfor}
If you want to insert HTML into your generated document, you can also have a look at the HTML services.
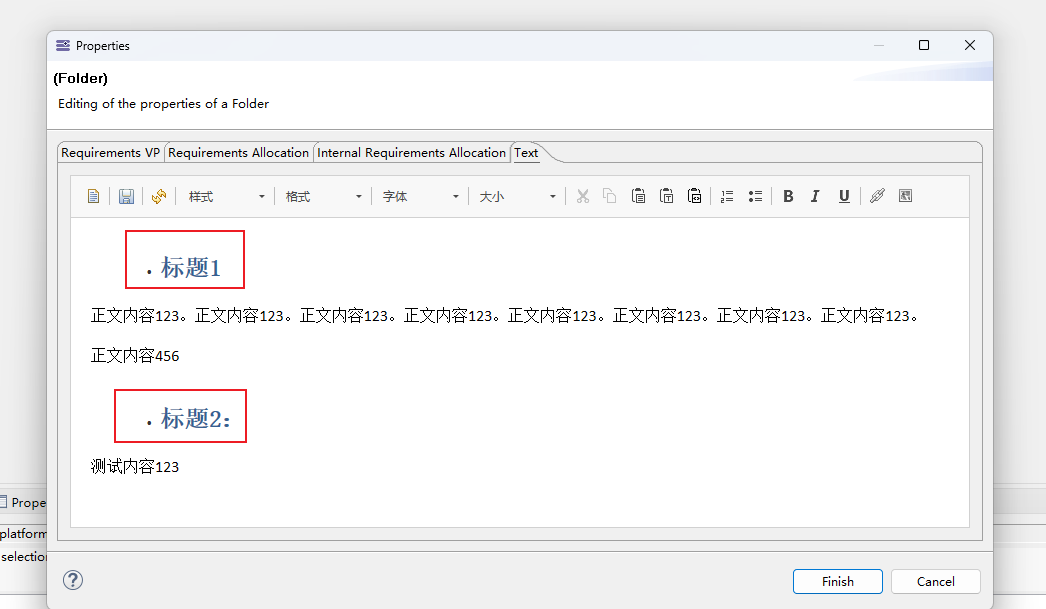
You will have to filter your input by yourself. You can use a custom Java service for this. Unless you have specific HTML/CSS code for those paragraphs. For instance if you have a bullet, you could filter on the <li> tag:
folder.toString().replaceAll('(\r\n)|\n','\n').tokenize('\n')->select(l | l.contains('<li>'))
thank you! I guess I should study Java for this.
Last question, how to separate image and text ?
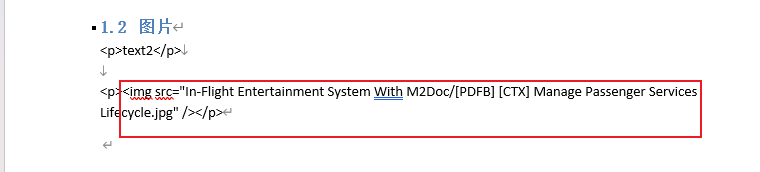
If you create your own Java service, you can reuse the M2DocHTMLParser. The parse() method will return a list of MElement. You can then filter MImage or other MElement.
1 Like